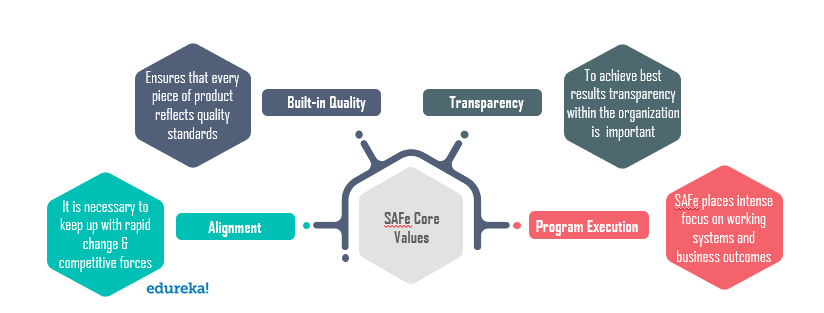
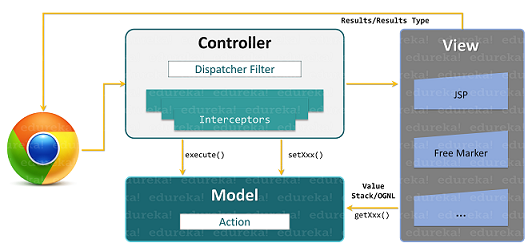
„Spark vs Hadoop“: kuri yra geriausia didžiųjų duomenų sistema?
Šiame tinklaraščio įraše kalbama apie apache spark vs hadoop. Tai suteiks jums idėją apie tai, kurią „Big Data“ sistemą reikia pasirinkti pagal skirtingus scenarijus.

Šiame tinklaraščio įraše kalbama apie apache spark vs hadoop. Tai suteiks jums idėją apie tai, kurią „Big Data“ sistemą reikia pasirinkti pagal skirtingus scenarijus.
Šis tinklaraštis padeda suprasti, kaip įdiegti ir nustatyti „sbteclipse“ papildinį, pateikiant nuosekliąsias instrukcijas, kaip paleisti „Scala“ programą „Eclipse IDE“.
Šiame tinklaraščio įraše paaiškinama, kodėl po „Hadoop“ turite pradėti naudotis „Apache Spark“ ir kodėl išmokę „Spark“ įvaldę hadoopą, galite padaryti stebuklus jūsų karjerai!
Ši „Apache Drill“ mokymo programa suteikia jums visą informaciją, kurios reikia norint pradėti naudoti „Apache Drill“ užklausų variklį, naudojimą su „Hadoop“, „Big Data & Apache Spark“.
Šis „Spark Hadoop“ tinklaraštis nurodo viską, ką reikia žinoti apie „Apache Spark combByKey“. Raskite vidutinį vieno studento balą naudodami „combByKey“ metodą.
„Apache Falcon“ yra nauja „Hadoop“ ekosistemos duomenų valdymo platforma, kuri supaprastina „feedoop“ grupių tiekimo procesą ir valdymą. Sužinokite, kaip jį nustatyti.
Šis „Apache Spark“ tinklaraštis išsamiai paaiškina „Spark“ akumuliatorius. Sužinokite „Spark“ akumuliatoriaus naudojimo pavyzdžius. Kibirkščių akumuliatoriai yra kaip „Hadoop Mapreduce“ skaitikliai.
Sužinokite viską apie „Apache Flink“ ir „Flink“ klasterio nustatymą šiame tinklaraštyje. „Flink“ palaiko realaus laiko ir paketinį apdorojimą ir yra „Big Data Analytics“ būtina „Big Data“ technologija.
Šiame tinklaraščio įraše aptariamas paskirstytasis talpinimas su transliuojamaisiais kintamaisiais ir pradedama efektyviai paskirstyti dideles vertes programuojant „Spark“.
CCA ir CCP „Cloudera“ sertifikatai pakeitė CCDH ir CCSHB egzaminus. Šis tinklaraštis nurodo viską, ką reikia žinoti apie naujus sertifikatus.
Šiame tinklaraščio įraše aptariami reikšmingi pokyčiai su „Spark Streaming“. Sužinokite viską apie duomenų paketais stebėjimą naudojant valstybinius D srautus.
Šiame tinklaraščio įraše aptariamos reikšmingos „Spark Streaming“ pertvarkos. Sužinokite viską apie kaupiamąjį „Hadoop Spark“ karjeros stebėjimą ir įgūdžių tobulinimą.
„Hadoop“ ir „Big Data“ technologijos daro perversmą sveikatos priežiūros analitikoje. Šie dideli sveikatos priežiūros tinklaraščio duomenys aptaria, kaip didelių duomenų analizė gali pagerinti medicininę priežiūrą.
Šis tinklaraščio įrašas apie „Hadoop Streaming“ yra nuoseklus vadovas, skirtas išmokti rašyti „Hadoop MapReduce“ programą „Python“, norint apdoroti didžiulius didelių duomenų kiekius.
Šis „Big Data Tutorial“ tinklaraštis suteikia jums pilną „Big Data“ apžvalgą, jų ypatybes, programas ir „Big Data“ iššūkius.
Šis „HDFS Tutorial“ tinklaraštis padės suprasti HDFS arba „Hadoop“ paskirstytą failų sistemą ir jos funkcijas. Taip pat trumpai išnagrinėsite pagrindinius jo komponentus.
Šiame „Splunk“ vadovėlyje supraskite „Splunk“ ir „ELK“ bei „Sumo Logic“ skirtumus ir nustatykite, kuris iš šių įrankių jums labiausiai tinka.
Šiame „Splunk“ naudojimo atvejų tinklaraštyje suprasite, kaip „Domino“ pica naudojo „Splunk“, kad gautų įžvalgų apie vartotojų elgseną. Ir suformuluokite savo verslo strategijas.
Ši pamoka yra žingsnis po žingsnio, norint įdiegti „Hadoop“ grupę ir sukonfigūruoti ją viename mazge. Visi „Hadoop“ diegimo veiksmai yra skirti „CentOS“ kompiuteriui.
Šiame tinklaraštyje kalbama apie įvairias HDFS komandas, tokias kaip „fsck“, „copyFromLocal“, „expunge“, „cat“ ir kt., Kurios naudojamos valdant „Hadoop“ failų sistemą.