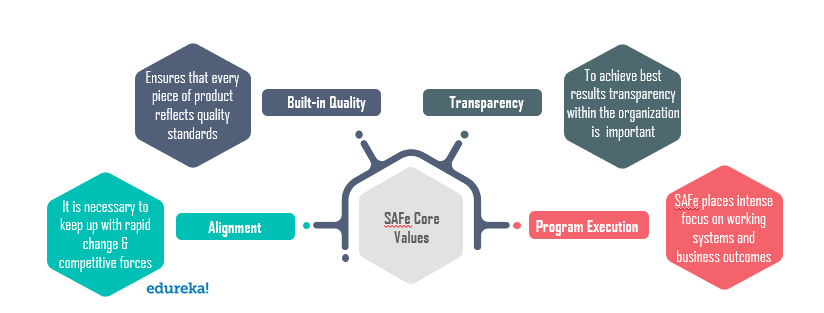
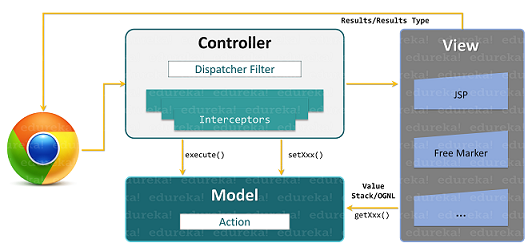
„Hadoop“ administratoriaus atsakomybė
Šiame tinklaraštyje apie „Hadoop Admin“ pareigas aptariama „Hadoop“ administravimo sritis. „Hadoop“ administratoriaus darbai yra labai paklausūs, todėl mokykitės „Hadoop“ dabar!

Šiame tinklaraštyje apie „Hadoop Admin“ pareigas aptariama „Hadoop“ administravimo sritis. „Hadoop“ administratoriaus darbai yra labai paklausūs, todėl mokykitės „Hadoop“ dabar!
„Apache Spark“ pasirodė kaip puiki didelių duomenų apdorojimo raida.
„Apache Hadoop 2.x“ sudaro reikšmingi „Hadoop 1.x“ patobulinimai. Šiame tinklaraštyje kalbama apie „Hadoop 2.0 Cluster Architecture Federation“ ir jos komponentus.
Tai suteikia supratimą apie „Job tracker“ naudojimą
„Apache Pig“ turi kelias iš anksto nustatytas funkcijas. Įraše pateikiami aiškūs UDF kūrimo „Apache Pig“ žingsniai. Čia kodai parašyti „Java“ ir reikalinga „Pig Library“
„HBase Storage“ architektūrą sudaro daugybė komponentų. Pažvelkime į šių komponentų funkcijas ir žinokime, kaip rašomi duomenys.
„Apache Hive“ yra duomenų saugojimo paketas, sukurtas ant „Hadoop“ ir naudojamas duomenų analizei. Avilys skirtas tiems vartotojams, kuriems patogu naudotis SQL.
Didžiausias „Apache Spark“ su „Hadoop“ diegimas, kurį vykdo geriausios įmonės, rodo jo sėkmę ir potencialą, kai reikia apdoroti realiuoju laiku.
„NameNode High Availability“ yra viena iš svarbiausių „Hadoop 2.0“ funkcijų. „NameNode High Availability“ su „Quorum Journal Manager“ naudojama redagavimo žurnalams dalytis tarp aktyvių ir budėjimo vardų mazgų.
„Hadoop“ kūrėjo darbo pareigos apima daugybę užduočių. Darbo pareigos priklauso nuo jūsų domeno / sektoriaus. Šis vaidmuo yra panašus į programinės įrangos kūrėją.
„Hive“ duomenų modeliuose yra šie komponentai, pvz., Duomenų bazės, lentelės, skaidiniai ir kibirai arba grupės. „Hive“ palaiko primityvius tipus, tokius kaip sveikieji skaičiai, plūdės, dvigubai ir eilutės.
Šios 4 priežastys, kodėl reikia pereiti prie „Hadoop 2.0“, kalba apie „Hadoop“ darbo rinką ir apie tai, kaip ji gali padėti paspartinti jūsų karjerą, suteikdama jums galimybę naudotis didžiulėmis darbo galimybėmis.
Šiame tinklaraštyje mes atliksime avilių ir verpalų pavyzdžius „Spark“. Pirmiausia sukurkite avilį ir verpalus ant „Spark“ ir tada galėsite paleisti avilio ir verpalų pavyzdžius ant „Spark“.
Šio tinklaraščio tikslas yra išmokti perkelti duomenis iš SQL duomenų bazių į HDFS, kaip perkelti duomenis iš SQL duomenų bazių į NoSQL duomenų bazes.
„Cloudera“ sertifikuotasis „Apache Hadoop“ (CCDH) kūrėjas yra karjeros postūmis. Šiame įraše aptariami pranašumai, egzaminų modeliai, studijų vadovas ir naudingos nuorodos.
Šiame tinklaraštyje pateikiama HDFS didelio prieinamumo architektūros apžvalga ir tai, kaip paprastais veiksmais nustatyti ir sukonfigūruoti HDFS didelio prieinamumo grupę.
„Apache Kafka“ ir toliau yra populiari kalbant apie „Real-Time Analytics“. Štai pažvelgti į tai iš karjeros pusės, aptarti karjeros galimybes ir darbo reikalavimus.
„Apache Kafka“ teikia didelio pralaidumo ir keičiamo dydžio susirašinėjimo sistemas, todėl yra populiari tikralaikėje analizėje. Sužinokite, kaip „Apache kafka“ mokymo programa gali jums padėti
Šis tinklaraščio įrašas yra gilus pasinerimas į Kiaulę ir jos funkcijas. Rasite demonstracinę versiją, kaip galite dirbti su „Hadoop“ naudodami „Pig“, nepriklausydami nuo „Java“.
Šiame tinklaraštyje aptariamos „Hadoop“, „Java“ pagrindų, reikalingų norint išmokti „Hadoop“, sąlygos ir atsakymai „Ar jums reikia„ Java “, kad išmoktumėte„ Hadoop “, jei žinote kiaulę, avilį, HDFS.