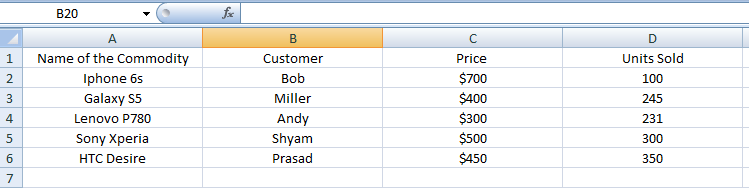
„HBase“ mokymo programa: „HBase“ įvadas ir „Facebook“ atvejų analizė
Šis „HBase“ mokymo tinklaraštis supažindina jus su „HBase“ ir jo funkcijomis. Tai taip pat apima „Facebook Messenger“ atvejų analizę, siekiant suprasti „HBase“ pranašumus.

Šis „HBase“ mokymo tinklaraštis supažindina jus su „HBase“ ir jo funkcijomis. Tai taip pat apima „Facebook Messenger“ atvejų analizę, siekiant suprasti „HBase“ pranašumus.
Šis tinklaraštis yra vadovas, kaip įdiegti „Lėlių meistrą“ ir „Lėlių agentą“. Jame taip pat pateikiamas „Apache Tomcat“ diegimo pavyzdys naudojant „Puppet Tomcat“ modulį.
Šis tinklaraštis yra nuoseklus „Apache Pig“ diegimo „Linux“ aplinkoje vadovas. Mes įdiegsime „Apache Pig 0.16.0“ ir paleisime jį skirtingais režimais.
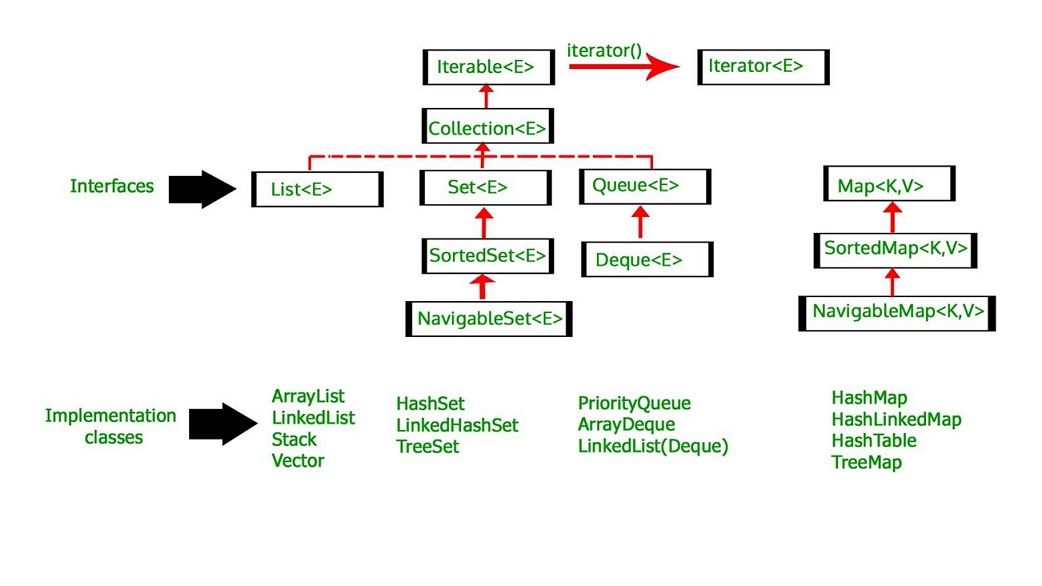
Šiame tinklaraštyje apie „HBase Architecture“ paaiškinamas HBase duomenų modelis ir pateikiama įžvalga apie HBase architektūrą. Tai taip pat paaiškina skirtingus HBase mechanizmus.
Šis avilio mokymo tinklaraštis suteikia jums išsamių žinių apie avilio architektūrą ir avilio duomenų modelį. Tai taip pat paaiškina NASA „Apache Hive“ atvejo tyrimą.
Šis „Spark Streaming“ tinklaraštis supažindins jus su „Spark Streaming“, jo funkcijomis ir komponentais. Tai apima „Sentiment Analysis“ projektą, naudojant „Twitter“.
Šis „Spark MLlib“ tinklaraštis supažindins jus su „Apache Spark“ mašininio mokymosi biblioteka. Tai apima filmų rekomendacijų sistemos projektą, kuriame naudojama „Spark MLlib“.
Šis „GraphX“ mokymo tinklaraštis supažindins jus su „Apache Spark GraphX“, jo funkcijomis ir komponentais, įskaitant skrydžio duomenų analizės projektą.
Šiame „Apache Flume“ mokymo tinklaraštyje paaiškinami „Apache Flume“ pagrindai ir funkcijos. Taip pat bus demonstruojamas „Twitter“ srautas naudojant „Apache Flume“.
„Apache Sqoop“ mokymo programa: „Sqoop“ yra įrankis duomenims perduoti tarp „Hadoop“ ir reliacinių duomenų bazių. Šis tinklaraštis apima „Sooop“ importą ir eksportą iš „MySQL“.
„Apache Oozie“ mokymo programa: „Oozie“ yra darbo eigos planavimo sistema, skirta valdyti „Hadoop“ užduotis. Tai yra keičiama, patikima ir išplečiama sistema.
„Big Data“ programos daro perversmą organizacijose ir padeda joms priimti informatyvesnius verslo sprendimus analizuojant didelius duomenų kiekius.
„Apache Spark“ perėmė „Big Data & Analytics“ pasaulį, o „Python“ yra viena iš labiausiai prieinamų programavimo kalbų, kuri šiandien naudojama pramonėje. Taigi čia, šiame tinklaraštyje, sužinosime apie „Pyspark“ (kibirkštis su pitonu), kad gautume geriausią iš abiejų pasaulių.
Šiame tinklaraštyje daugiausia dėmesio skiriama „Apache Hadoop YARN“, kuris buvo pristatytas „Hadoop“ 2.0 versijoje išteklių valdymui ir darbų planavimui. Tai paaiškina YARN architektūrą su jos komponentais ir kiekvieno iš jų atliekamomis pareigomis. Aprašoma „Apache Hadoop YARN“ programos pateikimo ir darbo eiga.
Šiame „PySpark Tutorial“ tinklaraštyje sužinosite apie „PSpark“ API, kuri naudojama dirbant su „Apache Spark“ naudojant „Python“ programavimo kalbą.
Šiame „PySpark Dataframe“ mokymo tinklaraštyje sužinosite apie „Apache Spark“ transformacijas ir veiksmus su keliais pavyzdžiais.
Šis „Edureka“ tinklaraštis „Cloudera Hadoop“ mokymo programoje suteiks jums išsamią informaciją apie skirtingus „Cloudera“ komponentus, tokius kaip „Cloudera Manager“, „Siuntiniai“, „Hue“ ir kt.
Šiame įraše aprašoma apie „Hadoop“ ir „NoSQL“ įgūdžių paklausos padidėjimą IT ir kitose srityse. skaitykite toliau, kad pamatytumėte, kaip padės „Hadoop“ ir „NoSQL“ įgūdžiai
Šiame tinklaraštyje aptariami „Hadoop“ diegimo pranašumai, „Hadoop“ iniciatyvos, „Hadoop“ mažose ir didelėse organizacijose bei „Hadoop“ mokymo nauda karjerai.
„Hadoop“ tapo karštu įgūdžiu, kurį reikia įgyti IT grandinėje, „Hadoop“ besimokančiųjų skaičius kiekvieną dieną smarkiai auga.